
Mental Models for Data and AI, Part 1: Why Silos Persist
The data warehouse of the 1990s, the data lake of the 2010s and today's GenAI platform fail surprisingly often for the same reasons. Three decades, three generations of technology, one set of mistakes. That is difficult to explain if the problem is the technology. My...

Big Context, Little Content: Why the LLM Context Window Is Not a Data Lake
Big context, little content - that is the short summary of what research tells us about large LLM context windows. Vendors advertise one million tokens as if capacity were the same as capability. Load everything in, the message goes, and the model will sort it out....

GenAI Critical Thinking: The Skill AI Cannot Replace
GenAI critical thinking is becoming one of the scarcest skills in knowledge work. GenAI makes it easier than ever to get answers. What it does not do is make it easier to question them. That asymmetry sits at the heart of a shift that affects not just data management,...

Open Table Formats: From Vendor Lock-In to Data Sovereignty
Open table formats like Apache Iceberg and Delta Lake are changing how companies store analytical data - and who controls it. If you store your analytical data in a proprietary format, you're locked in - to the engine, the tooling, the license costs. The data belongs...

Value Over Volume: Why AI Makes Data Professional Fundamentals Matter More Than Ever
Data professional fundamentals have never been more valuable, yet for years the industry measured progress by volume: lines written, data products shipped, pipelines grown, dashboards created. AI has now exposed how little these metrics ever said about actual impact....
From Heart Rate to H3: Six Ways to Think About Your Running Data in Oracle 26ai
I'm a passionate runner. And like many data enthusiasts, I can't resist collecting data about the things I care about. This post is both a personal reflection on my training and a hands-on tour of how Oracle can model very different questions - from streets you run...

The Art Of Data Tech Unlearning: Which Habits We Need to Drop Now
In the rapidly evolving landscape of 2026, Data Tech Unlearning has become a critical survival skill for architects and leaders. In the data world, we often define ourselves by the complexity of the tools we’ve mastered. Someone who spent years taming Spark clusters...
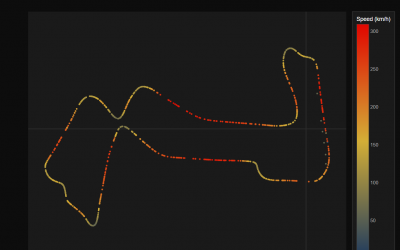
One Database, Six Workloads: Analyzing F1 Telemetry With Oracle Converged Database
The Complexity We Created Somewhere along the way, we convinced ourselves that specialized databases were the answer to everything. Need to store documents? Spin up DocumentDB X1. Time series data? Here's TimeseriesDB X2. Graph relationships? GraphDB X3. Vector...

The Data House: Strategy, Governance, Management, Security – Explained and Separated
In AI and data programs, a surprising amount of friction doesn’t come from technology - it comes from language. Terms like data strategy, data governance, data management, security, privacy, and compliance are often used interchangeably, even though they answer...

From Ticket-Takers to Value-Makers: Navigating 2026 Tech Predictions
In late 2025, the tech world is drowning in “2026 tech predictions” from every analyst and hyperscaler in the industry. But behind the buzzwords lies a shift that will define the next decade: the transition from technical execution to business judgment. What follows...

Agentic AI with DuckDB and smolagents: Natural Language Queries for Analytics
Agentic AI with DuckDB turns natural language queries for analytics from a nice idea into something you can actually run today. Many users don’t want to think in joins, window functions, or aggregate clauses — they just want answers. Here I’ll walk through how I use...

Data and Analytics Skills 2026+: Why You Need More Than a Full Toolbox
The demands on data professionals and leaders are changing rapidly. Technologies, methods and tools come and go – and with LLMs like ChatGPT, generic knowledge is increasingly automatable. This makes one question even more important: how do I position myself so that...