Reference to blogs, tweets, discussions, etc that caught my attention during the last week.
Data Architecture
“Hyper-threading – how does it double CPU throughput?” by Aurimas Mikalauskas shows some interesting tests with Hyper-threading turned on and provoked some good responses. Craig Shallahamer did tests in 2011 on his blog article “Core vs Thread…CPU Utilization – Part 1” because he observed Oracle database servers exhibiting more power then the number of CPU cores could provide.
“The Stunning Scale Of AWS And What It Means For The Future Of The Cloud” by Todd Hoff lists some stats about Amazaon AWS. Complete control allows to get the quality they need which means that e.g. networking gear or networking software is custom built to fit perfectly their own needs. It also handles the issue of ever-growing data volumes with networking getting more and more the bottleneck including costs.
Data Flow
“On Data Curation. Interview with Andy Palmer” by Roberto V. Zicari covers the creation of a unified view of the data. The adressed tool is Tamr which is claimed to complement ETL tools by machine learning algorithms. The research paper “Data curation at scale: the Data Tamer System” by Stonebraker, Bruckner, etc describes the approach.
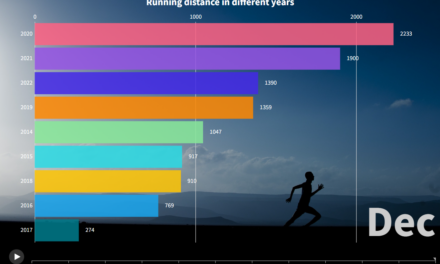
Data Visualization
StackExchange dashboard with performance statistics visualization (e.g. CPU load, DB size, queries/sec, etc).