Most distributed databases do not offer ACID transactions. The support of linear scalability is the main reason that distributed NoSQL databases like MongoDB, Cassandra, AWS DynamoDB and many others have reduced transactional support. Abadi et al. propose in a paper (Calvin: Fast Distributed Transactions for Partitioned Database Systems) a scheduling and replication layer to achieve ACID compliance without high contention costs.
Distributed transactions
Distributed transactions have a problematic shout, especially if a two-phase commit is used: performance or scalability in general will suffice. Transactions are very useful for supporting the programmer to implement the business logic. Applications that are not easily partitionable will be complex to implement without strong consistency guarantees.
So it’s no wonder that ACID is rarely seen in distributed databases. The authors propose a solution to implement ACID transactions in distributed systems without causing long locks on data. These transactions can span multiple partitions across a shared-nothing cluster.
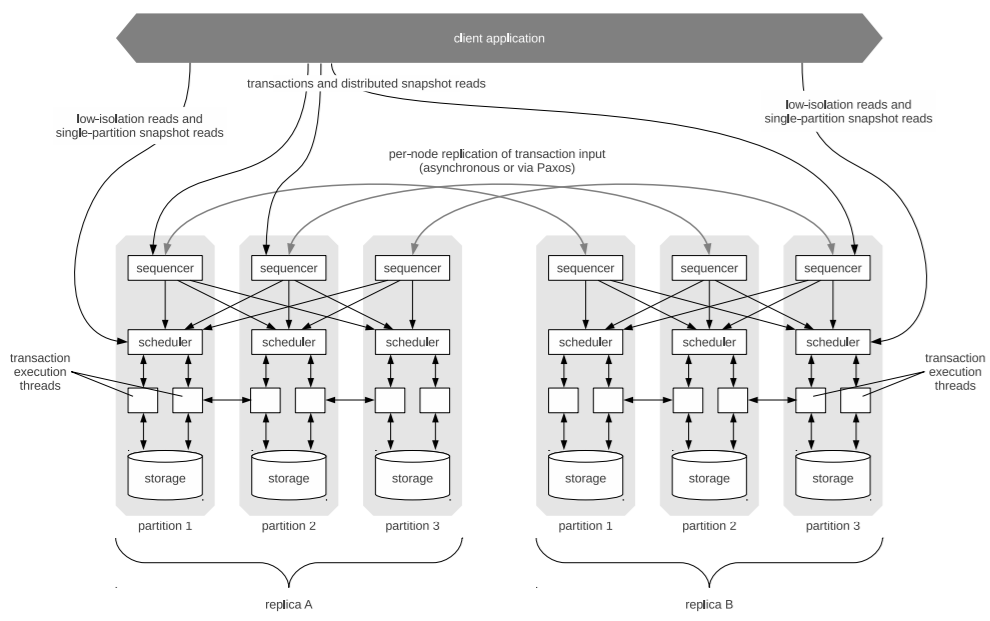
Architecture – sequencer, scheduler, storage
The main idea behind Calvin is that nodes agree on a plan before any lock is set or the actual transaction begins. Each node has to follow the deterministic plan in the very same order. Even if a node fails, the transaction completes as the node can follow-up later.
The sequencer compiles the plan. The sequencer is one of the three layers, as shown in the architecture diagram. The sequencer collects operations for 10ms intervals and creates a micro-batch. Micobatches are replicated across sequencers. After the completion of replicating a micro-batch, the sequencer sends a message to the scheduler on every partition within its replica.
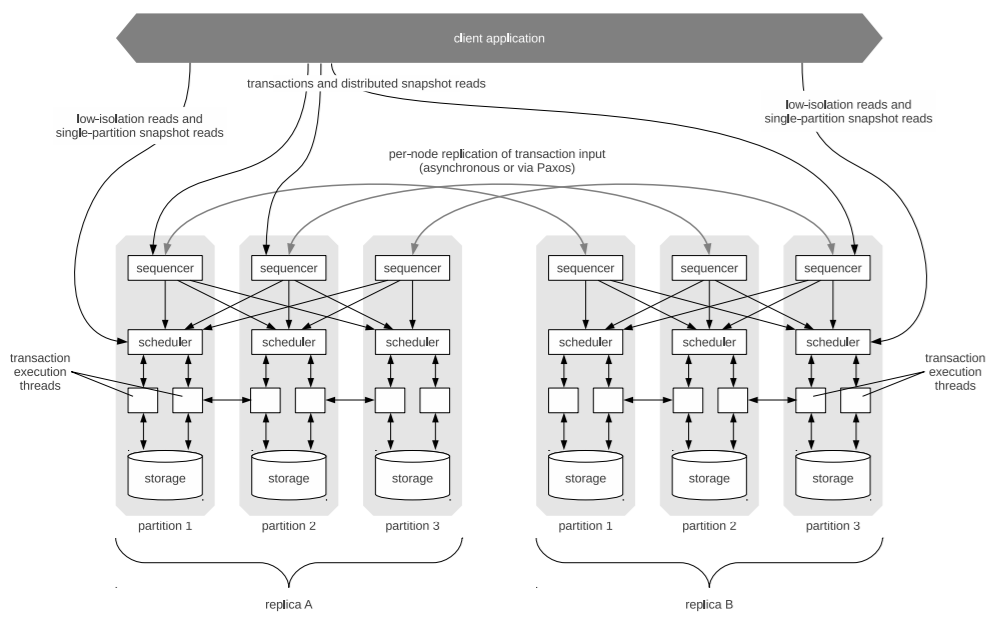
Executing the transaction is done in the second layer, which is called the scheduler. Any CRUD (create, read, update, delete) storage engine can use Calvin: the physical data layout is part of the storage layer (third layer).
Performance
The performance of the disks is a main challenge with deterministic execution. A transaction may have to wait until data is read from disk into the cache. The transaction will block all subsequent transaction even if the other transactions access different data. Therefore Calvin prefetches data to avoid such wait conditions. The sequencer must know which keys are in memory across all storage nodes to start a prefetch before the scheduler starts the micro-batches. The authors ran subsets of TPC-C benchmark and concluded that Calvin performs better for systems with very high contentions compared to two-phase commit implementations.
FaunaDB
FaunaDB is an implementation of Calvin. FaunaDB is a multi-model DB supporting, e.g. graph and document store. There are also some blog posts by the vendor on the difference to Google’s Spanner, which depends on clock synchronization to achieve ACID transactions. Daniel Abadi (advisor of FaunaDB) also wrote about Calvin vs Spanner.