TDWI 2018 took place in Munich from 25-JUN-2018 to 28-JUN-2018. This blog post summarizes some of my impressions on the topics AI, Data Catalog and Automation&Agility.
Artificial Intelligence
AI was the main topic in many sessions. I joined Barry Devlin’s session “From BI to AI via Analytics and IOT.” Barry Devlin published his first paper on Data Warehousing 30 years ago. His recent book “Business unIntelligence: Insight & Innovation beyond Analytics & Big Data” appeared in 2013. On TDWI, he talked about the journey from BI to AI. Some of his key points:
- Logistics and management are crucial to putting AI into production
- The emergence of edge analytics for IOT: immediate analysis on IOT device or edge server
- Automation (current focus on faster & cheaper) and augmentation are vital drivers
- Beware of bias – trained algorithms will get our bias


His conclusions at the end of his presentation were:
- AI will build the future. Start now
- Decision making reinvented automate and augment
- Reimage ethics, economics, and society anew
Data Catalog
Data Catalogs were a hot topic with several talks covering the subject. E.g., BARC organized a session with a 15-min pitch of some vendors. Current tools still lack a variety of essential features like metadata versioning. Automatic discovery of entities and correlations will become a selling point to avoid a manual mapping between technical and business metadata. A blog post on Data Catalogs can be found here.
Data Catalogs are central for Zalando on their way to datadevops. Sebastian Herold from Zalando and Arif Wider from ThoughtWorks introduced their ideas about a “Manifesto for a DevOps-like Culture Shift in Data & Analytics.”
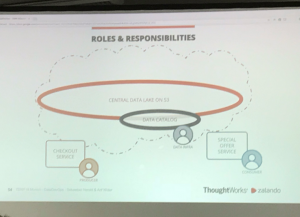
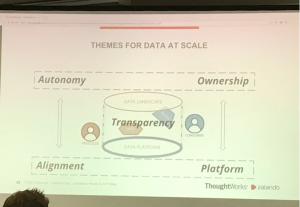
The speakers introduced five themes for data at scale:
- Autonomy: teams need to have a critical size so that autonomous teams that can operate independently to create their service.
- Alignment: an agree on high-level goals is necessary so that autonomous teams can go into a compatible direction.
- Ownership: Teams will be able to drive all tasks by themselves if they possess the full ownership. The work has to be done where there is interest in the outcome.
- Platform thinking: you need a central data platform. All systems/ingestions have to provide metadata!
- Transparency: people need to understand the data. Therefore metadata s paramount, e.g., from where does data come?

Distributed responsibilities about data and analytics require data at scale for a culture shift towards DataDevOps. The photo shows Zalando’s DataDevOps manifesto. Advantages for product teams resulting from the manifesto are:
- Independence to work with data
- No dependencies between teams
- Simplicity to consume data produced by others
Michael Müller-Wünsch from OTTO talked in his keynote about “data-driven platform management @OTTO.” Data as an asset is still at the very beginning. There is still a long way ahead to understand questions like
- How much value is in a dataset?
- Is it worthwhile to keep the value of a data set or even increase its value?
OTTO currently invests 20% of its technology budget into BI and analytics. That may still be not enough according to the keynote speaker. But he also addressed the responsibility to determine if data is allowed to use. Always keep in mind that digitalism has a social component.
Automation and Agility
DWH and Big Data Automation in combination with agility is still an important topic. Gregor Zeiler emphasized the importance to
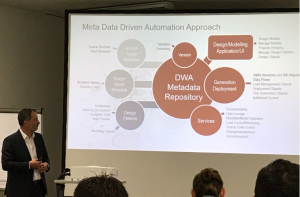
- design/model metadata on a logical level
- use design patterns to generate code for different platforms/technologies/architecture/modeling.
Tools or requirements are changing rapidly, so it is beneficial to exchange the target platform or architecture and “just” generate again. Additionally, it is important to model on a logical level as the physical level is very dependent on the chosen tools/databases/etc. The logical data modeling level has its challenges, too.
I talked about “Data integration and Data Vault – the devil is in the details.” Hub, Link, Sat sounds easy. If you start modeling with Data Vault, you soon notice that there are many modeling choices. It is not that easy as it seems without proper training/ knowledge/practice. Data modeling training is regularly neglected compared to the training of tools. Modeling techniques, architectures, concepts are valid for a long time – tool knowledge has a limited lifespan until the next tool version appears or another tool replaces the old one. Time pressure, design flaws in source systems, lousy data quality additionally contribute to the challenge to derive a good data model. Finally some tweets about the session: