The first NoSQL databases were created in the 2000s. Companies like Google, Amazon, Twitter & Co have developed their own databases for their specific needs. Over time, many of these databases were made available as open source. This blog post gives an overview of NoSQL, NewSQL, and cloud-native databases.
NoSQL databases
In the 2000s, a variety of databases emerged, which are summarized as NoSQL. These databases are characterized by the fact that data storage is distributed, replication is used, high availability is achieved, and data is not stored in tables as known from SQL databases. Not using SQL as query language avoids the so-called impedance mismatch that occurs when objects of an object-oriented programming language are stored in an SQL database.
NoSQL is based on particular physical implementation models, which are no longer universally applicable compared to SQL databases. These NoSQL implementation models fulfill a specific purpose (use case) only. There are four different NoSQL database categories:
- Key Value Stores
- Document stores
- Wide-column stores (Wide-columnar stores)
- Graph stores
Key Value Stores
Key value stores provide an easy-to-understand physical model. Data can be easily distributed and thus achieve high scalability. Key-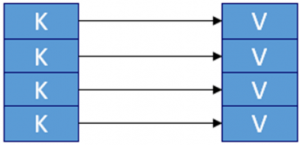 value stores are often used as caches, either as a stand-alone database or as a caching layer for specific data between the application and an SQL database. The figure shows the physical model. Key-value stores consist of a unique access key (Key) and user data (Value). The user data may be varied, e.g., a single value or complex structures. Operators are put, get and delete. Typically, only the key can be indexed. Oracle NoSQL, Redis, Amazon Dynamo, Riak, are typical representatives of this category. The transition to document stores is fluid. For example, Oracle NoSQL also has Document Store properties.
value stores are often used as caches, either as a stand-alone database or as a caching layer for specific data between the application and an SQL database. The figure shows the physical model. Key-value stores consist of a unique access key (Key) and user data (Value). The user data may be varied, e.g., a single value or complex structures. Operators are put, get and delete. Typically, only the key can be indexed. Oracle NoSQL, Redis, Amazon Dynamo, Riak, are typical representatives of this category. The transition to document stores is fluid. For example, Oracle NoSQL also has Document Store properties.
Document stores
Document stores are based on a physical model in which complex data structures (“documents”) are assigned to a key. The 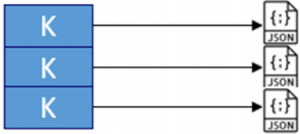 physical model is shown in the figure. Such documents are typically JSON (JavaScript Object Notation) or XML structures. Access to data is not just by using the key compared to key-value stores, but also using an access key. For this purpose, the indexing of document data as an access key is necessary to enable a high-performance search.
physical model is shown in the figure. Such documents are typically JSON (JavaScript Object Notation) or XML structures. Access to data is not just by using the key compared to key-value stores, but also using an access key. For this purpose, the indexing of document data as an access key is necessary to enable a high-performance search.
JSON is supported for serialization of many database systems as primary (e.g., MongoDB, CouchDB, Couchbase) or additional data format. JSON structures allow the embedding of many data elements in a document, e.g., personal data including addresses and blog articles. Due to this denormalization, joins are avoided. On the other hand, updates are particularly complex due to denormalization. A standard query language like SQL usually is not available for Document Stores. Proprietary languages, some of which inherit SQL-like elements, must be used to create, modify and delete documents. For example, there are operations such as insertOne or insertMany for inserting one or more documents.
Wide-column stores (Wide-columnar stores)
Wide-columnar stores use a physical model consisting of any number of columns. Individual rows can have different columns 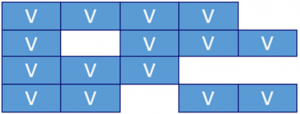 (see figure). The cells of columns can contain atomic data or complex structures such as documents. Access is by using the row key. These databases are highly scalable when writing and reading a few records using the key. Table scans have to be avoided as these scans will slow down performance and scalability. The most well-known representatives of this category are Cassandra and HBase as part of the Hadoop stack. A Cassandra deployment scenario is the storage of equipment features when customizing a vehicle in a web-based online vehicle configurator.
(see figure). The cells of columns can contain atomic data or complex structures such as documents. Access is by using the row key. These databases are highly scalable when writing and reading a few records using the key. Table scans have to be avoided as these scans will slow down performance and scalability. The most well-known representatives of this category are Cassandra and HBase as part of the Hadoop stack. A Cassandra deployment scenario is the storage of equipment features when customizing a vehicle in a web-based online vehicle configurator.
Graph stores
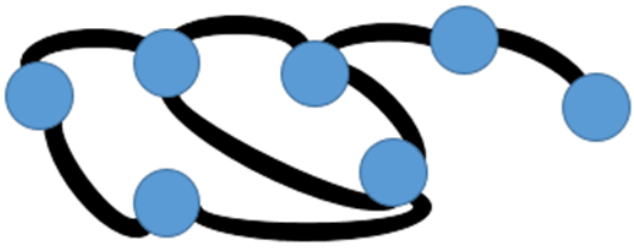
Graph databases also belong to the NoSQL category, although scalability and distribution are not among the strengths of these  data stores. These databases store data as nodes and edges (see figure). The mapping of relationships is the main application of Graph databases. These databases enable a high-performance traversing of edges. Neo4j is the most well-known database of this category.
data stores. These databases store data as nodes and edges (see figure). The mapping of relationships is the main application of Graph databases. These databases enable a high-performance traversing of edges. Neo4j is the most well-known database of this category.
Multi-model databases
NoSQL DBs have a specialized physical model. Multi-model databases try to overcome the limited range of possible use cases by combining several of these NoSQL models into a single database. Examples are OrientDB, MarkLogic or Microsoft Cosmos DB.
ACID, BASE, and CAP
ACID is a well-known property of transactions in SQL databases to ensure consistency – consistency is often softened in NoSQL. According to Brewer’s CAP theorem, a distributed system can take two of the following properties: consistency, availability and partitioning tolerance. AP systems impose strict consistency in favor of availability and resilience. For these databases, the BASE principle (Basically Available, Soft state, Eventual consistency) applies. Consistency occurs over time as soon as all distributed database nodes have received the change. The behavior of an application without a strict consistency can be observed regularly on Twitter, for example, new followers are listed by name, but the number of followers is often updated later.
The following example shows the effects of BASE. Assuming the value of the variable X is 1, it executes the operations X = 5 and then on another network node Y = X + 2. A system with strict consistency will return the value 7. A BASE system, on the other hand, provides 3 or 7 or, after some time, only 7. A very readable article on CAP and BASE is written by Daniel Abadi.
NewSQL databases
The lack of strict consistency in the persistence layer makes an application very complicated. The transfer of consistency assurance into the app proves to be too challenging, too time-consuming, and too prone to error. In a white paper on the NewSQL database F1, Google puts the problem in a nutshell: “So we have a lot of experience with eventual consistency systems at Google. In all such systems, we find out that they are extremely complex and error-prone mechanisms to cope with eventuality. We think this is an unacceptable burden to place on and. Full transactional consistency is one of the most important properties of F1 “.
Even SQL as a standardized query language was quickly identified as necessary. Databases like VoltDB or MemSQL promise the flexibility of NoSQL as well as essential features like strict consistency and SQL. Even NoSQL databases like MongoDB got some kind of ACID features recently – ACIDless has no future.
Cloud-native databases
Cloud native is the latest trend and is based on distribution, replication and high availability like NoSQL and NewSQL. Cloud native databases are ideally designed for use in the cloud. Properties of such applications are defined by the cloud-native Computing Foundation (CNCF):
- Ubiquitous and flexible: the DB must be able to run in any container technology in any cloud environment
- Resilient and scalable: The failure of nodes must not be noticeable due to high availability, redundancy, and automatic failover
- Dynamic: Upgrades are automatically run
- Automatable: everything is automated in the sense of an Infrastructure as Code
- Observable: logging, tracing, metrics must also be available when the container no longer exists
- Distributed: leveraging the benefits of a distributed cloud
Examples of cloud-native databases are Google Spanner with the open source variant CockroachDB, YugaByte DB, and FaunaDB.
Outlook
How are the SQL database vendors responding to the challenges posed by NoSQL, NewSQL, and cloud-native databases? In the past, there have already been additions that have long since flowed into the SQL standard:
- In the 1990s, object-oriented concepts were integrated as a response to object-oriented databases
- In the 2000s, XML concepts were integrated as a response to XML databases
If the use of a NoSQL, NewSQL or cloud-ready database is considered, then security features must be viewed critically (“enterprise readiness”). SQL databases have rich and mature security features. “Young” databases have some catching up to do, so that a required security feature may be missing. There are no excuses for security compromises.
There are also answers to the challenges posed by NoSQL, NewSQL and cloud-native databases:
- A flexible physical model for schema-on-read through JSON support (SQL standard 2016)
- Autonomous DBs for specific scenarios to reduce tuning and operational activities
- Further long-known measures, e.g., through informational (deferred) constraints, partitioning, parallelization, etc.
NoSQL, NewSQL and cloud-ready databases will remain in contrast to object-oriented or XML databases. These have already secured an outstanding share of the overall market, and these data stores make sense for specific use cases.

