PostgreSQL columnar extension cstore_fdw is a storage extension which is suited for OLAP-/DWH-style queries and data-intense applications. Columnar analytical databases have unique characteristics compared to row-oriented data access.
Many commercial products exist:
- Pure columnar analytical databases like Vertica, Exasol, Snowflake (cloud-only), Amazon Redshift (cloud-only), Google BigQuery (cloud-only) are ideal for analytical workloads only.
- SAP Hana is optimized for columnar analytical workload but also supports row-oriented workload (OTLP-style). Classical row-oriented databases like Oracle, SQL Server, or Db2 LUW have columnar analytical extensions (Oracle DBIM, SQL Server columnstore indexes, Db2 shadow tables / Db2 BLU).
There are also some open-source alternatives:
- Clickhouse is a pure columnar analytical database.
- PostgreSQL and MySQL store data row-oriented but have column-oriented add-ons, e.g. PostgreSQL cstore_fdw extension.
The blog post
- first explains the characteristics of columnar analytical databases (see chapter “Characteristics of columnar analytical databases”),
- then introduces the data used in the article and how to reproduce the examples (see chapter “data preparation”),
- finally shows the usage of cstore_fdw extension (see chapter “PostgreSQL columnar extension cstore_fdw”),
Characteristics of columnar analytical databases
There are some essential characteristics of columnar analytical databases which are described in this chapter. Columnar analytical databases are SQL databases and should not be confused with wide-columnar databases like HBase or Cassandra. Wide-columnar databases are completely different: they support an OLTP-style workload with heavy writes and short scans.
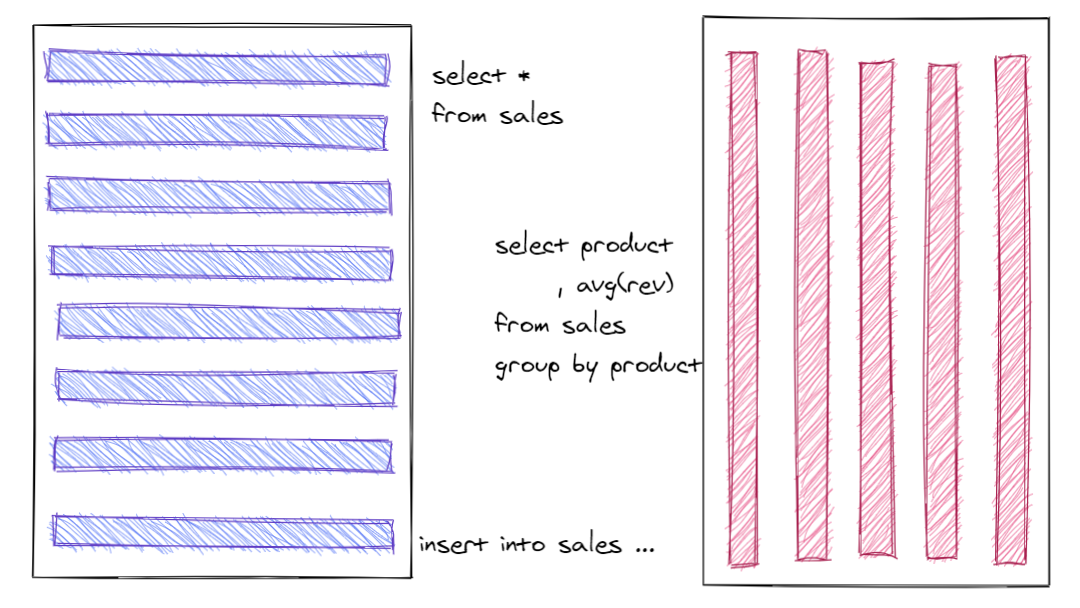
Columnar storage
The picture shows the classical row-oriented storage usually used in OLTP systems and columnar storage for analytical applications. Columnar storage organises data physically by storing columns in blocks (pages, in-memory units) instead of rows.
OLTP applications typically have many small read (select <many columns> from <table>) and write operations (insert, update, select). Such operations work very well with row-oriented storage.
Analytical or data-intense applications typically read many rows and aggregate a few columns only (select col1, max(col2), avg(col3) from <table> group by col1 or similar). Such operations work very well with column-oriented storage.

Compression
Columnar-storage has the advantage that the same types of data is stored in a block. The compression ratio of such data is normally much higher compared to row-oriented storage. Compression algorithms like run-length encoding and/or lookup tables are commonly used.
In-Memory
All databases optimise fast memory (e.g. RAM, SSD) access for read and write operations. Columnar analytical databases normally benefit from the high compression to store more data in-memory.
Zone maps (index skipping)
Reading data is optimised by internal indexes. Minimum and maximum values are stored within blocks (or pages or memory units) to skip reading blocks out of range.
SIMD (vectorisation)
SIMD (single instruction, multiple data) allows the processing of multiple data during a single instruction, as shown in the image.

Data preparation
First, pull and run the container with version 1.2 from a command line. Port 5432 is exposed, and you must set a password for the postgres database user.
CREATE TABLE ranking
(
rank integer,
track_id varchar(32),
artist_id integer,
no_streams integer,
url character varying(200),
stream_date date,
region character varying(10)
);
COPY ranking
FROM ‘/usr/src/dwh_course/sourcedata/spotify/ranking.csv’ DELIMITER ‘,’ CSV HEADER;
SELECT * FROM ranking LIMIT 10;
SET max_parallel_workers_per_gather = 0;
The table also contains columns for the data of the streaming (stream_date), the number of streams (no_streams), the region of the stream (region with values ‘de’ or ‘global’) and the position in the charts (rank). Finally, the URL points to the track.
Parallelism is switched off for better comparison of the explain plan outputs.

PostgreSQL columnar extension cstore_fdw
Cstore_fdw is an extension for PostgreSQL. The source code is open source. Citus Data developed the extension and explains it at github.
My docker container includes the extension and can be used for tests. The next sections show how to use the container and how to create a columnar table.
CREATE EXTENSION cstore_fdw;
CREATE SERVER cstore_server FOREIGN DATA WRAPPER cstore_fdw;
The extension is configured for a database (and not instance/cluster-wide).
The columnar functionality comes as an extension (cstore_fdw) that needs to be created in a PostgreSQL database. In the next step, a foreign data wrapper is created. The foreign data wrapper adds a foreign server that can be queried as the local PostgreSQL database.
The following screenshot shows the code and the output of the statements.

And now let’s create a columnar table.
CREATE FOREIGN TABLE ranking_columnar
(
rank integer,
track_id varchar(32),
artist_id integer,
no_streams integer,
url character varying(200),
stream_date date,
region character varying(10)
)
SERVER cstore_server
OPTIONS(compression ‘pglz’);
INSERT INTO ranking_columnar
SELECT * FROM ranking;
ANALYZE ranking;
ANALYZE ranking_columnar;
The first part of the code block creates a columnar table. The create table command contains the keyword “foreign” and references the foreign server at the end of the command combined with a compression algorithm. Default compression is none (no compression).
An insert fills the new ranking_columnar table, and the final statements compute statistics for ranking and ranking_columnar.
The following screenshot shows the code and the output of the statements.

Now let’s compare the costs for a query against a non-partitioned and a columnar table using cstore_fdw.
EXPLAIN
select date_part(‘year’, stream_date) as year, avg(no_streams)
from ranking
group by date_part(‘year’, stream_date);
EXPLAIN
select date_part(‘year’, stream_date) as year, avg(no_streams)
from ranking_columnar
group by date_part(‘year’, stream_date);
The screenshot below shows the output of the explain statements. A full table scan is on the non-partitioned table, causing much higher costs than the columnar table.

Note that the columnar table is compressed while the regular table is not compressed. Currently, PostgreSQL does not offer table compression.
The following command computes the size fo the tables.
SELECT relname
, pg_size_pretty(pg_total_relation_size(relid)) As “Size”
FROM pg_catalog.pg_statio_user_tables
WHERE relname = ‘ranking’
UNION
SELECT ‘ranking_columnar’, pg_size_pretty(cstore_table_size(‘ranking_columnar’));
The screenshot below shows the size of the regular, row-oriented uncompressed table and the column-oriented, compressed table.

Cstore_fdw limitations
Unfortunately, there are several limitations that reduce production readiness, e.g.:
- no primary and no foreign keys
- no partitioning support
- no updates/deletes
- no SIMD support
Partitioning is a powerful feature when working with many data. The article PostgreSQL partitioning guide shows how to use the various partitioning possibilities (range, list, hash). There is another interesting open source project for a PostgreSQL columnar storage engine going on. The project zedstore is still (Jan/2021) under development.
Summary
The article explains the PostgreSQL columnar extension cstore_fdw for DWH or data-intense applications. Column-oriented storage, high compression, In-Memory, index skipping, and vectorisation are some of the columnar analytical databases’ main characteristics. Cstore_fdw has its strengths but also still quite a lot of limitations.



